Gene interaction networks hold clues to disease susceptibility and treatment response
Credit: Raamesh Deshpande
When the Human Genome Project was completed, in 2003, it opened the door to a radical new idea of health – that of personalized medicine, in which disease risk and appropriate treatment would be gleaned from one’s genetic makeup. As more people had their genomes sequenced, disease-related genes would start coming into view– and while this is true in many ways, things also turned out to be much more complicated.
Sixteen years on, tens of thousands of people have had their genomes sequenced yet it remains a major challenge to infer future health from genome information. Part of the reason may be that genes interact with each other to modify trait inheritance in ways that aren’t totally clear, write Donnelly Centre researchers in an invited perspective for the leading biomedical journal Cell.
“All the genome sequencing data is highlighting the complexity of inheritance for the human genetics community,” says Brenda Andrews, University Professor and Director of U of T’s Donnelly Centre for Cellular and Biomolecular Research and a senior co-author, whose lab studies interactions between genes. “The simple idea of a single gene leading to a single disease is more likely to be an exception than a rule,” she says.
Andrews and Charles Boone, who is also a senior co-author, are professors in U of T’s Donnelly Centre and the Department of Molecular Genetics, as well as Senior Fellows of the Genetic Networks program at the Canadian Institute for Advanced Research, which Boone co-directs.
Genome wide association studies, or GWAS, which scan the genomes of patient populations and compare them to healthy controls, have unearthed thousands of mutations, or genetic variants, that are more prevalent in disease. Most variants are found in common diseases that affect large swathes of the world’s population but their effects can be small and hard to see. Instead of there being a single gene for heart disease or schizophrenia, for example, there may be many combinations of subtle genetic changes scattered across the genome that tune up or down a person’s susceptibility to these diseases.
Vast genetic diversity in the human population further influences trait inheritance while environmental effects, such as diet and upbringing, further complicate matters.
In some cases, a single gene variant can be extremely potent and cause a disease, as seen in cystic fibrosis, heamophilia and other inherited disorders. But even two people with the same disease variant can experience a wildly different disease severity which, presently, cannot be gleaned from their genomes. Even more astonishing, sequencing studies have identified people who carry damaging mutations but remain perfectly healthy, presumably protected by other, as yet unknown gene variants within their genomes.
“It would be a simpler problem if one particular mutation resulted in Disease X all of the time, but that’s often not the case,” says Michael Costanzo, Senior Research Associate in Boone’s lab and one of the authors on the paper. “To understand the effect of combinations of variants is really difficult. We suspect it’s particular sets of mutations that really impact what the disease outcome is going to be in a personal genome” says Costanzo. “How genes interact with each other is important and, given our current understanding of gene-gene interactions, it’s not a problem that’s easily solved by reading individual genome sequences.”
It’s a numbers game as most genome analysis methods lack the statistical power to confidently uncover multiple genes behind a disease. An often-cited calculation, by researchers at the Broad Institute in Boston, states that to identify a single pair of genes underlying a disease, on the order of half a million patients would have to have their genomes sequenced, with another half a million of healthy people as controls. “If most genetic diseases involve gene combinations, collecting enough patient data to find these interactions is a huge challenge,” says Costanzo.
Genetic interactions – what are they and how can they be identified?
“The concept of genetic interaction is simple, but the physiological repercussions can be profound,” write the authors. Two genes are said to interact if a combined outcome of their defects is bigger or lesser than expected from their individual outcomes. For example, a person carrying a mutation in either gene A or in gene B can be healthy, but if both A and B don’t work, disease occurs.
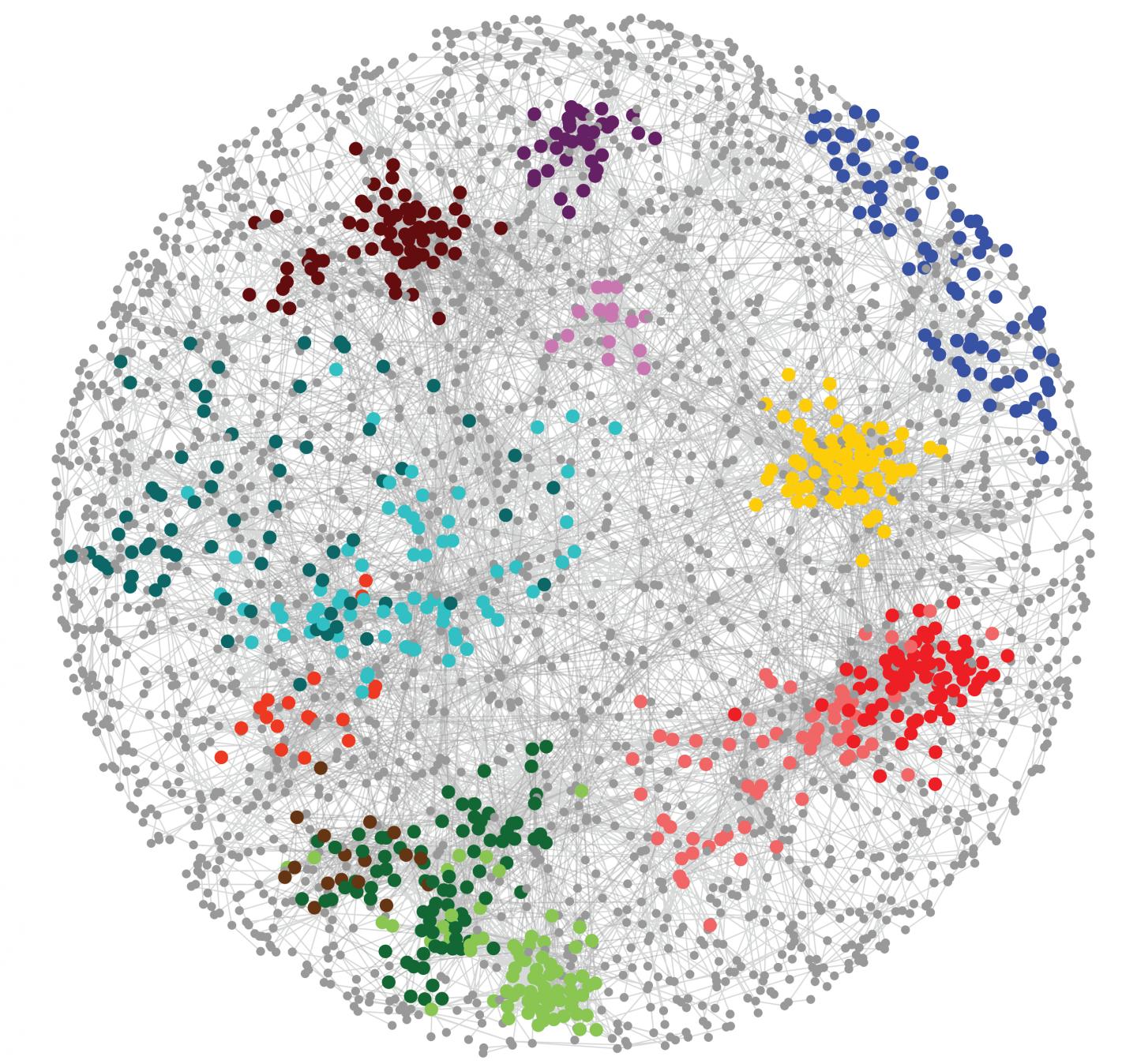
Research in simple model organisms–most notably yeast–has mapped genome-wide genetic interactions revealing how thousands of genes organize into functional groups within a network. From this, basic principles emerged, allowing researchers to predict a gene’s function and its relative importance for the cell’s health based on its position in the network. Studies also revealed the identity of so-called “modifier genes” which can suppress the effect of damaging mutations and how genetic background influences trait inheritance.
These types of studies rest on the researchers’ ability to switch off genes in precise combinations to find the ones that work together. For human genes, however, such tools did not exist until very recently.
That’s all changed now thanks to the gene editing tool CRISPR with which human genes can be turned off in any combination with ease. Although no genome-wide map is yet available, early work indicates that the same principles uncovered in model organisms also apply to human genes. This is already helping reveal function of the less studied human genes and how they relate to disease. And with new computational approaches, it is becoming possible to integrate findings from model organisms with incoming human data to achieve an emerging glimpse of more meaningful insights about health from genome information.
Genetic interactions and cancer therapy
Freed from normal checks and balances, cancer cells stockpile mutations in their genomes and this sets them apart from healthy cells in a way that can be exploited for therapy. Knowing how genes interact in cancer holds promise for the development of selective drugs that kill only sick cells and leave healthy ones unharmed.
“Cancer is a genetic disease and ultimately the genetic wiring of a cancer cell is a product of mutations that occur its genome and we want to understand that,” says Jason Moffat, a co-author on the paper and a professor of molecular genetics in the Donnelly Centre whose lab uses CRISPR to map genetic interactions in cancer cells. “With CRISPR, we can start to systematically map how genes interact in cancer cell lines in a similar fashion to how geneticists have mapped genetic interactions in yeast,” he says.
This work has the potential to reveal distinct drug targets for different forms of disease. The goal is to find a drug that synergizes with a mutation that’s only found in a type of cancer. The drug would then kill sick cells more precisely and with fewer side effects than chemotherapy or radiotherapy.
The knowledge of genetic interactions will also help shed light on why so many approved cancer drugs only work in some patients and not others.
“We can’t think about genes in isolation anymore,” says Boone. “We have to start looking at variants of multiple genes as a major component of genetic disease, because those combinations are going to be different for different people and these specific combinations may not only profoundly affect disease susceptibility, but they will likely dictate new personalized therapies.”
###
Media Contact
Jovana Drinjakovic
[email protected]
Original Source
http://www.
Related Journal Article
http://dx.


{kind=link}