Adversarial training has emerged as the primary line of defense against adversarial attacks in machine learning models, playing a crucial role in enhancing their robustness. However, recent studies reveal a troubling imbalance in the effectiveness of adversarial training across different classes in classification tasks. This class-wise discrepancy in robustness presents significant challenges that could undermine the integrity of machine learning applications. Such inequities create what is known as the “buckets effect,” where the least robust class becomes a significant vulnerability, allowing adversaries to exploit it. Moreover, ethical dilemmas arise when certain groups receive protection against adversarial attacks at the expense of others, leading to uneven defensive capabilities across various demographics and applications.
To mitigate these pressing concerns, researchers have begun exploring methodologies that ensure robust adversarial training is not only effective but also fair. This focus was sharply highlighted in a groundbreaking study led by Qian Wang and his team, which recently published their findings in the highly regarded journal, Frontiers of Computer Science. Their research introduces a novel algorithm known as FairAT, which stands for fair adversarial training. FairAT stands out by specifically addressing the disparities in robustness among different classes, aiming to level the playing field in the training of machine learning models.
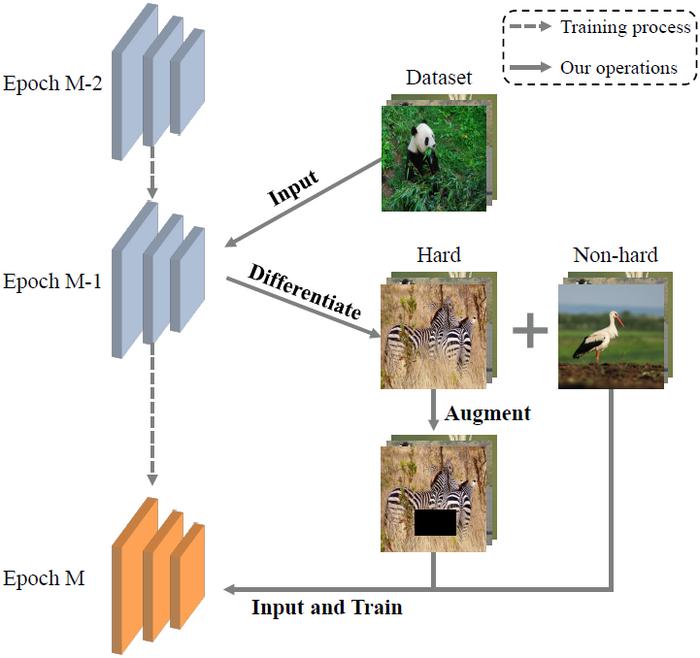
The underlying principle of FairAT involves harnessing the connection between the uncertainty models exhibit towards various examples and the robustness levels associated with those examples. By identifying and emphasizing hard classes during the training process, the algorithm dynamically augments the training data. This enhancement allows the adversarial training process to focus more on examples that are likely to be misclassified or overlooked by standard methods, effectively improving robustness and ensuring fairness throughout the training phase.
One of the most innovative aspects of FairAT is its ability to use uncertainty as a fine-grained indicator of robust fairness. Traditional adversarial training methods often overlook the nuances of class-wise performance, resulting in a one-size-fits-all approach that fails to adequately address the unique challenges posed by different classes. In contrast, FairAT’s targeted approach recognizes that not all adversarial examples are created equal; some classes are more challenging than others and require additional focus and adaptation.
Through dynamic augmentation of difficult examples, FairAT has demonstrated not just an increase in overall robustness but also an improved balance in performance across classes. The algorithm outperforms state-of-the-art methods, thereby setting a new benchmark in the field of adversarial training. This advancement is of paramount importance, given that the practical application of machine learning systems hinges on their ability to operate fairly and effectively across diverse real-world scenarios.
The implications of this research are manifold. Fair adversarial training could pave the way for more ethically designed algorithms in critical areas such as healthcare, law enforcement, and finance, where model decisions impact human lives. Ensuring that no group is unfairly disadvantaged or left vulnerable to exploitation is not only a technical challenge but also a moral one. With FairAT, there lies an opportunity to bridge this gap and foster an inclusive approach to machine learning that prioritizes fairness alongside performance.
As the field continues to evolve, there will be a pressing need for further research directed at enhancing fairness methodologies. Future studies could delve into more sophisticated techniques that refine the adjustment processes within FairAT, reducing training costs while maintaining high standards of accuracy and fairness. Furthermore, the extension of these strategies into other modalities and tasks could see the principles of FairAT applied broadly, transforming how machine learning models are developed and deployed in practice.
In terms of implementation, the FairAT algorithm requires a careful consideration of the training environment and data diversity. Researchers and practitioners must ensure that training datasets used reflect the nuances of the real world to evoke a comprehensive understanding of class robustness. This comprehensive data representation will ultimately lead to more equitable and reliable models.
Moreover, the feedback mechanism inherent in FairAT provides a fascinating approach to machine learning, where models are equipped to learn from their own uncertainties. As models evolve alongside their training data, this iterative improvement becomes central to achieving lasting effectiveness in combating adversarial threats. The potential for FairAT to foster a more responsive form of adversarial training presents an exciting frontier for machine learning research.
In conclusion, the introduction of FairAT represents a critical leap towards not only enhancing the robustness of machine learning models but also addressing the ethical implications of their deployment. By prioritizing fairness in adversarial training, the research team led by Qian Wang has opened new avenues for achieving reliable and responsible AI. As the commitment to fairness in technology gains momentum, the work of these researchers will undoubtedly influence future discussions and developments in the field.
Subject of Research:
Article Title:
News Publication Date:
Web References:
References:
Image Credits:
Keywords
Tags: addressing the buckets effectadversarial training techniqueschallenging examples in adversarial trainingclass-wise robustness disparitiesdemographic considerations in AI securityenhancing machine learning integrityequitable defense against adversarial attacksethical implications of AIFairAT algorithm for adversarial trainingfairness in machine learningimproving model resilience against attacksrobustness in classification tasks

{kind=link}