
Artificial intelligence (AI) has significantly transformed countless domains, from healthcare to transportation, by harnessing vast amounts of data for training sophisticated models. The efficacy of these AI systems largely hinges on the quality and quantity of data available during training. In recent years, as practitioners have begun to exhaust traditional datasets, the realm of synthetic data has emerged as a critical player in overcoming data scarcity. However, the challenge with synthetic data is not merely quantity; it is also about ensuring quality. Researchers have recently turned their focus toward methods for evaluating the quality of synthetic datasets, an often-overlooked dimension in AI model training.
In a groundbreaking study, a collaboration led by Wei Gao, an associate professor of electrical and computer engineering at the University of Pittsburgh’s Swanson School of Engineering, has made strides in addressing this issue. Working alongside researchers from Peking University, Gao and his colleagues have crafted analytical metrics aimed at qualitatively evaluating the quality of synthetic wireless data. This innovative framework is poised to enhance task-driven training in AI models utilizing synthetic datasets, particularly in the context of wireless data applications.
Their findings are meticulously documented in the research paper titled “Data Can Speak for Itself: Quality-Guided Utilization of Wireless Synthetic Data,” which was recently honored with the Best Paper Award at the MobiSys 2025 International Conference. This recognition underscores the significance of their work in the field of mobile systems and applications, where the role of data, particularly synthetic data, is pivotal.
The crux of the study zeroes in on the essential characteristics of synthetic data—specifically affinity and diversity. These qualities are particularly crucial when considering training AI models across various modalities, such as images, videos, or sound. The researchers contend that generating high-quality synthetic data, especially in the context of wireless signals, presents unique challenges. Gao notes that an effective model must utilize data that accurately represents the physical world, avoiding bizarre artifacts—like faces with multiple eyes—that can lead to model failures.
Furthermore, the researchers stress the importance of diversity in synthetic datasets. For an AI model trained to recognize human faces, it is imperative that the training data encompasses a wide variety of facial features rather than being loaded with thousands of images depicting the same individual. Gao articulates that “AI models learn from variation,” thus requiring that synthetic datasets provide both fidelity to real-world conditions and a broad spectrum of instances.
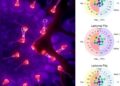
In addressing synthetic wireless data specifically, Gao and his team employed a task-specific approach to assess the quality of generated data. They examined existing algorithms for data synthesis, discovering a troubling trend where the majority of synthetic datasets offer good diversity yet falter in affinity, particularly in the challenging domain of wireless signals. This presents significant implications for applications in technologies such as home monitoring and interactive gaming, where accurate recognition of human behavior in signal patterns is critical.
Wireless signals, fundamentally different from visual or auditory data, are complex waveforms that can be difficult for researchers to interpret and assess. Gao’s findings illustrate that current synthetic wireless datasets suffer from issues of low affinity, which can lead to improper data labeling and compromised task performance. Recognizing the urgency of improving data quality in this domain, the team explored semi-supervised learning techniques as a means to enhance affinity.
By leveraging a limited set of labeled synthetic samples verified as legitimate, Gao and his team trained their models to understand what constitutes acceptable data. This novel methodology culminated in the development of SynCheck, a framework designed to filter out low-affinity wireless synthetic samples while intelligently labeling remaining samples during iterative training cycles. The results of their endeavors were impressive, revealing a notable 4.3% increase in model performance, in stark contrast to a performance decline of 13.4% when synthetic data was utilized indiscriminately.
This pioneering research marks a significant milestone, addressing the critical need for not just a continuous influx of synthetic data but also ensuring its quality for the advancement of AI models. As the intersection of AI and synthetic data continues to evolve, methodologies established through Gao’s research may pave the way for future innovations, facilitating more accurate and effective AI systems capable of performing complex tasks across a myriad of industries.
Efforts to enhance the evaluation and generation of synthetic data are fundamental to the advancement of AI technologies. As industries increasingly turn to AI-driven solutions, the integrity and quality of the data—both real and synthetic—will be paramount to the successful deployment of these systems. Continued research in this area promises to foster improvements in not only model accuracy but also the reliability of AI applications in areas where human behaviors need to be deciphered from intricate signal patterns.
In conclusion, the collaboration between Gao and his team and their international counterparts exemplifies the urgent need for qualitative assessments of synthetic data. By emphasizing the importance of both affinity and diversity in synthetic datasets, they are laying the groundwork for more robust AI models that can better understand and interpret complex environments. The implications of their work could reach far beyond wireless applications, influencing a wide range of AI disciplines and contributing to our overall understanding of the role synthetic data will play in the future of intelligent systems.
Subject of Research:
Article Title: Data Can Speak for Itself: Quality-Guided Utilization of Wireless Synthetic Data
News Publication Date: [Insert Publication Date Here]
Web References: [Insert any relevant web references here]
References: [Insert any relevant references here]
Image Credits: [Insert any relevant image credits here]
Keywords
Tags: advancements in synthetic dataset utilizationAI model training methodologiesartificial intelligence in wireless applicationscollaboration in AI researchdata scarcity solutions in AIevaluating synthetic datasets for AI trainingimpact of data quality on AI efficacyimplications of wireless data depletioninnovative metrics for data assessmentsynthetic data quality evaluationtask-driven training for AI modelswireless data sources and connectivity issues


{kind=link}