
In a significant advancement for computational technologies, a team of researchers from the Tokyo University of Science has introduced an innovative system known as the Dual Scalable Annealing Processing System (DSAPS). This groundbreaking system uniquely enables the simultaneous scaling of both spin numbers and interaction bit widths, which are crucial factors in effectively solving combinatorial optimization problems (COPs). Timothy Kawahara, a leading figure in the field and Professor in the Department of Electrical Engineering at the university, spearheaded this pivotal research.
Combinatorial optimization problems are prevalent across various domains including logistics, finance, and pharmaceuticals. These problems involve finding an optimal solution from a finite set of possible configurations, often leading to computational complexities that become exponentially challenging as the size and number of constraints increase. Traditionally, CPU-based computations have found such tasks arduous due to their resource-intensive nature, necessitating the exploration of alternative methods such as annealing processors. These specialized hardware systems employ principles from statistical mechanics to navigate the solution landscape of COPs more adeptly.
Annealing processors utilize the Ising model, which conceptualizes variables of optimization problems as magnetic spins and their constraints as interactions between these spins. This framework allows for solutions that minimize the system’s energy, leading to effective resolutions of optimization problems. However, the traditional implementations of the Ising model have often grappled with limitations regarding scalability and precision, particularly when it comes to the dichotomy of sparsely-coupled versus fully-coupled Ising models.
The sparsely-coupled models excel in scalability, permitting a higher number of spins; however, they require users to reformulate their problems to fit within this model. Conversely, fully-coupled models grant direct mapping of any COP without transformation, making them highly advantageous. Unfortunately, they have inherently restricted capacities, limiting the number of spins and the bit width of interactions. Building on previous efforts that employed application-specific integrated circuits (ASICs) to enhance capacity within fully-coupled models, significant hurdles remained regarding fixed interaction bit width, complicating the resolution of specific COPs.
The introduction of DSAPS marks a revolutionary pivot in addressing these challenges. The innovation lies in its dual-scalability mechanism, adeptly combining both capacity and precision within a singular, scalable structure. By employing advanced methodologies for manipulating the energy computation blocks, referred to as ∆E blocks, DSAPS provides a transformative approach to improving the efficiency and accuracy of COP solutions.
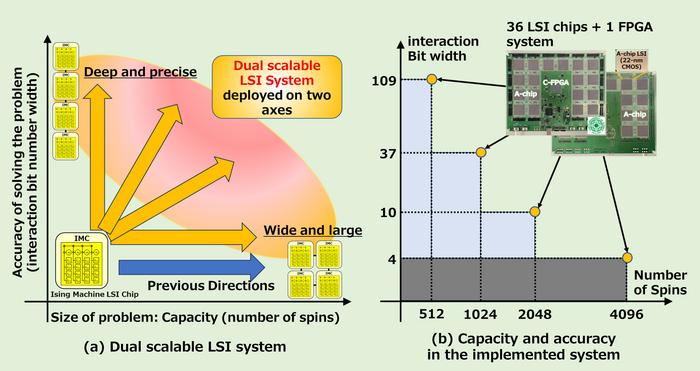
Each ∆E block represents a large-scale integrated (LSI) chip situated on a complementary metal-oxide-semiconductor (CMOS)-based annealing processing board. The team achieved scalability by constructing a high-capacity structure that allows the division of each ∆E block into smaller sub-blocks for independent calculations. The results from these sub-blocks can then be aggregated by a central control block, thereby increasing the overall number of spins by subdividing the computational resources effectively.
On the front of precision, the high-precision structure of the DSAPS system allows for multiple ∆E blocks, managing identical spin counts and interactions while executing calculations at varying bit levels. This versatility enables the control block to amalgamate their computations through bit shifts, effectively enhancing the overall interaction bit width of the system. This sophisticated architecture signifies that a system harnessing four ∆E blocks—each operating at different bit levels—can exponentially manage computations compared to earlier models.
The prototype configurations of DSAPS realized on a CMOS-AP board included one with 2048 spins combined with 10-bit interactions across four threads, and another configuration showcasing 1024 spins, featuring 37-bit interactions with just two threads. This conceptual leap delineates a substantial advancement over traditional ASICs, which remain substantially limited with interaction bit widths ranging typically between 4 to 8 bits.
Validation tests conducted for various scenarios—including the MAX-CUT problems—illustrated a remarkable accuracy exceeding 99% when juxtaposed against the best-known theoretical results. In exploring the intricacies of the 0-1 knapsack problem, the researchers duly noted an extensive average deviation of 99% in the DSAPS configuration with 10-bit interactions. In stark contrast, the 37-bit configuration maintained an average deviation of merely 0.73%, aligning closely with the results exhibited in CPU-based emulation tests. This variance underscores the critical importance of selecting the appropriate DSAPS configuration based on the specific characteristics and requirements of the target combinatorial optimization problem.
Professor Kawahara, reflecting on the implications of this technology, remarked that the DSAPS system not only represents a leap toward solving complex real-world COPs but also serves as a fundamental educational tool. He announced that starting in 2025, this revolutionary system would be incorporated into the curriculum for third-year electrical engineering students, thus enhancing the educational framework surrounding semiconductor design and optimization methodologies.
Overall, the significance of the research extends far beyond academic exploration. The pronounced advancements exhibited by the Dual Scalable Annealing Processing System echo promising applications across diverse fields, signifying transformative shifts in how large-scale optimization problems can be addressed. The integration of higher spin counts and broader interaction widths into a coalesced system represents a crucial evolution in the quest for efficient and effective computational solutions. The ongoing collaboration at Tokyo University of Science remains devoted to pioneering paths in fully-coupled Ising machines, which could redefine problem-solving capabilities on multiple fronts.
The dual scalability provided by DSAPS stands poised to overcome the challenges faced by traditional methodologies, thereby heralding an era of rapid advancements in multiple application domains. As the field of computational optimization evolves, systems like DSAPS will undoubtedly forge new pathways for researchers and practitioners alike, expanding the landscape of what can feasibly be achieved within combinatorial optimization.
Subject of Research:
Dual Scalability in Annealing Processors
Article Title:
Dual Scalable Annealing Processing System That Scales Number of Spins and Interaction Bit Width Simultaneously
News Publication Date:
31-Mar-2025
Web References:
https://doi.org/10.1109/ACCESS.2025.3553542
References:
DOI: 10.1109/ACCESS.2025.3553542
Image Credits:
Credit: Takayuki Kawahara from Tokyo University of Science, Japan
Keywords
Tags: annealing processor technologycombinatorial optimization problemscomputational technologies advancementDual Scalable Annealing Processorsenergy minimization in optimizationIsing model applicationslogistics and finance optimizationoptimization solution techniquesresource-intensive computation alternativesspecialized hardware systemsstatistical mechanics in computationTokyo University of Science research



{kind=link}