Information sharing can lead to better, more accurate predictions when neural network mechanisms are concerned and by using shared information amongst groups of similarly-minded people, next-item recommendation technology can be improved over the current conventional methods.
Credit: Journal of Social Computing, Tsinghua University Press
Information sharing can lead to better, more accurate predictions when neural network mechanisms are concerned and by using shared information amongst groups of similarly-minded people, next-item recommendation technology can be improved over the current conventional methods.
Predictive technology might seem like magic, but in reality, it consists of thoughtfully constructed models that are in need of constant improvement to keep up with the ever-changing demands of a user’s preferences and requirements. Researchers interested in improving the session-based recommender systems (SBRSs) are looking to make more accurate predictions not only based on user’s interests but on the relationships of like-minded users to group similar interests together. This model takes into account long-term and short-term sessions and interests to create an intuitive, accurate predictive model that outperforms conventional, existing models in addition to predicting the need to develop new groups automatically based on the evolving interests and needs of the target users.
Researchers published their results in June 2023 in Journal of Social Computing.
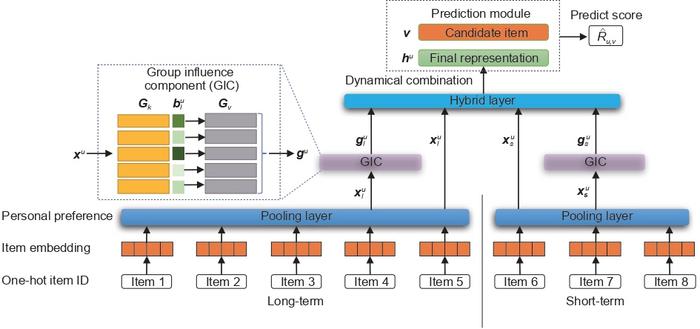
The developed model is based on long and short-term user groups (LSUGs) which can give a pretty decent idea of the user’s preferences and what future items would have the highest likelihood of interest.
“In all these approaches, user representations are summarized based on their sessions independently, causing the learned models to be built on a per-user basis. There is no explicit information sharing between the models of users,” said Nengjun Zhu, researcher and author of the study. The addition of information sharing between users who have shown to have similar interests creates a wider pool of information to learn from and therefore, a more accurate predictive next-item recommendation model can be developed.
“Session-based recommender systems are increasingly applied to next-item recommendations.
However, existing approaches encode the session information of each user independently and do not consider the interrelationship between users. This work is based on the intuition that dynamic groups of like-minded users exist over time,” said Zhu.
Utilizing the relationships between users with similar interests, the target user can be assigned to groups that have a high probability of overlapping or shared interests. The representation of these groups is then weighted in a way to estimate the probability of the predicted item being the next thing visited by the user.
A shortcoming of conventional methods that researchers aimed to address is the evolution of people’s interests and the possibility of new groups developing. In other models, this needs to be done manually which costs additional time and resources. Instead, the team of researchers opted to integrate an adaptive learning unit into the model to automatically determine whether there is a need for a new group to be made, and if so, to create that new group and learn what interests would comprise this new group.
The addition of this adaptive learning dynamic further establishes a higher level of probability that the next-item prediction will be useful and of interest to the target user when considering certain metrics. However, it is found that there is a point where the adaptive learning unit isn’t as effective when items are ranked all together using the area under curve (AUC) metric as opposed to just using positive examples as found in the Bayesian personalized ranking (BPR) method.
While the adaptive learning dynamic adds function and flexibility by creating new groups, it does not have the ability to delete or decrease groups that are no longer relevant; this is an area researchers wish to work on in the future in order to keep the user groups more streamlined and applicable to the user’s evolution of interests. Along the same lines, researchers would also like to utilize contrast learning to develop explicit differences between user groups to keep representation true to the user’s interests.
Nengjun Zhu and Lingdan Sun from the School of Computer Engineering and Science at Shanghai University, Jian Cao with the Department of Computer Science and Engineering at Shanghai Jiao Tong University, Xinjiang Lu of the Business Intelligence Lab at Baidu Research and Runtong Li of the Department of Electrical Engineering at Tsinghua University contributed to this research.
The National Natural Science Foundation of China and the Shanghai Youth Science and Technology Talents Program made this research possible.
##
About Journal of Social Computing
Journal of Social Computing (JSC) is an open access, peer-reviewed scholarly journal which aims to publish high-quality, original research that pushes the boundaries of thinking, findings, and designs at the dynamic interface of social interaction and computation. This will include research in (1)computational social science—the use of computation to learn from the explosion of social data becoming available today; (2) complex social systems or the analysis of how dynamic, evolving social collectives constitute emergent computers to solve their own problems; and (3) human computer interaction whereby machines and persons recursively combine to generate unique knowledge and collective intelligence, or the intersection of these areas. The editorial board welcomes research from fields ranging across the social sciences, computer and information sciences, physics and ecology, communications and linguistics, and, indeed, any field or approach that can challenge and advance our understanding of the interface and integration of computation and social life. We seek to take risks, avoid boredom and court failure on the path to transformative new paradigms, insights, and possibilities. The journal is open to a diversity of theoretic paradigms, methodologies and applications.
About SciOpen
SciOpen is a professional open access resource for discovery of scientific and technical content published by the Tsinghua University Press and its publishing partners, providing the scholarly publishing community with innovative technology and market-leading capabilities. SciOpen provides end-to-end services across manuscript submission, peer review, content hosting, analytics, and identity management and expert advice to ensure each journal’s development by offering a range of options across all functions as Journal Layout, Production Services, Editorial Services, Marketing and Promotions, Online Functionality, etc. By digitalizing the publishing process, SciOpen widens the reach, deepens the impact, and accelerates the exchange of ideas.
Journal
Journal of Social Computing
DOI
10.23919/JSC.2023.0013
Article Title
Enhancing Next-Item Recommendation Through Adaptive User Group Modeling
Article Publication Date
30-Jun-2023