Inflammatory signature of nonalcoholic fatty liver disease
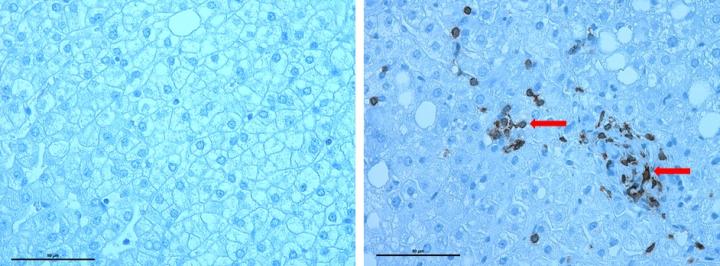
Credit: Rohit Kohli, MBBS, MS, Children's Hospital Los Angeles A team of investigators led by Rohit Kohli, MBBS, MS, of Children's Hospital Los Angeles, has...
Credit: Rohit Kohli, MBBS, MS, Children's Hospital Los Angeles A team of investigators led by Rohit Kohli, MBBS, MS, of Children's Hospital Los Angeles, has...
Credit: University of Utah Health SALT LAKE CITY – Air pollution trapped by winter inversions along Utah's Wasatch Front, the state's most populated region, is...

Credit: The Hong Kong Polytechnic University Hong Kong is renowned as the culinary capital of Asia, with local catering establishments of unique styles providing great...

Credit: Jan-Peter Kasper/FSU It is a gruesome spectacle that meets the eyes of Prasad Aiyar as he looks down the microscope. The doctoral candidate from...
Queen’s University Belfast are taking part in a global trial to test whether exercise should be prescribed to treat patients with advanced prostate cancer. The...

Credit: Enrique Rivero/UCLA The National Institute on Drug Abuse has awarded $5 million to researchers at UCLA to develop a resource and data center for...

Credit: Pixabay Amsterdam, May 1, 2017 – A new type of wound dressing could improve thousands of people's lives, by preventing them from developing infections....

Credit: Cedars-Sinai LOS ANGELES – Jan. 24, 2018 – Cedars-Sinai investigators have developed a new, more accurate set of guidelines for assessing the severity of...
Acapulco, Mexico 21 Nov. 2015: Doctors in Mexico have shown the benefits of a healthy diet and exercise in patients with heart failure, in research...

Backed by a growing body of research, investigators at Dana-Farber Cancer Institute are calling for all hospitals to establish bereavement programs for families of deceased...

Researchers at the University of Georgia are working to find the fastest way possible to treat and cure human African trypanosomiasis, long referred to as...

Credit: National University of Singapore Physical frailty is common among the elderly and is strongly associated with cognitive impairment, dementia and adverse health outcomes such...

Credit: Julie O'Connor, Wayne State University DETROIT – A research team led by Deborah Ellis, Ph.D., professor of family medicine and public health sciences in...

Credit: Children's Hospital Colorado Aurora, Colo. (Oct. 4, 2017) – Researchers from Children's Hospital Colorado and the University of Colorado Anschutz Medical Campus recently discovered...

Credit: Penn Medicine PHILADELPHIA – The National Minority Quality Forum (NMQF) has honored two members of the Penn community with its 40 Under 40 Leaders...
