Recently, model-based reinforcement learning has been considered a crucial approach to applying reinforcement learning in the physical world, primarily due to its efficient utilization of samples. However, the supervised learned model, which generates rollouts for policy optimization, leads to compounding errors and hinders policy performance. To address this problem, the research team led by Yang YU published their new research on 15 August 2024 in Frontiers of Computer Science co-published by Higher Education Press and Springer Nature.
The team proposed a novel model-based learning approach that unifies the objectives of model learning and policy learning. By directly maximizing the policy’s performance in the real world, this research proposes the Model Gradient algorithm (MG). Compared with existing model-based methods, this approach achieves both higher sample efficiency and better performance.
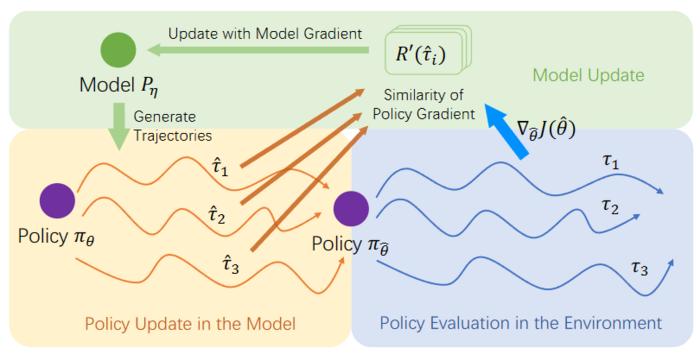
This research identifies the limitation of current supervised-learned model-based reinforcement learning methods, where the model inaccuracy leads to compounding error. The authors suggest addressing the problem by modifying model learning objective. A supervised model learning approach may not be designed to assist policy learning in achieving better performance because the objective does not align with the ultimate goal of reinforcement learning, i.e., maximizing the real-world policy performance. Therefore, this research aims to unify the objective of model learning and policy learning starting with policy gradient. By maximizing the real-world performance of the policy learned in the model, this research derives the gradient of model, which represents the direction of policy improvement with the form of enhancing the similarity between the policy gradient in the real environment and that in the model. By adopting this model update approach, the authors develops a novel model-based reinforcement learning algorithm called the Model Gradient algorithm (MG).
Experimental results demonstrate that MG outperforms other model-based reinforcement learning baselines with supervised model fitting in multiple continuous control tasks. MG especially exhibits stable performance in sparse reward tasks, even when compared to state-of-the-art Dyna-style model-based reinforcement learning methods with short-horizon rollouts.
For the future work, this research considers extending this form to more policy optimization such as off-policy methods.
DOI: 10.1007/s11704-023-3150-5
Recently, model-based reinforcement learning has been considered a crucial approach to applying reinforcement learning in the physical world, primarily due to its efficient utilization of samples. However, the supervised learned model, which generates rollouts for policy optimization, leads to compounding errors and hinders policy performance. To address this problem, the research team led by Yang YU published their new research on 15 August 2024 in Frontiers of Computer Science co-published by Higher Education Press and Springer Nature.
The team proposed a novel model-based learning approach that unifies the objectives of model learning and policy learning. By directly maximizing the policy’s performance in the real world, this research proposes the Model Gradient algorithm (MG). Compared with existing model-based methods, this approach achieves both higher sample efficiency and better performance.
This research identifies the limitation of current supervised-learned model-based reinforcement learning methods, where the model inaccuracy leads to compounding error. The authors suggest addressing the problem by modifying model learning objective. A supervised model learning approach may not be designed to assist policy learning in achieving better performance because the objective does not align with the ultimate goal of reinforcement learning, i.e., maximizing the real-world policy performance. Therefore, this research aims to unify the objective of model learning and policy learning starting with policy gradient. By maximizing the real-world performance of the policy learned in the model, this research derives the gradient of model, which represents the direction of policy improvement with the form of enhancing the similarity between the policy gradient in the real environment and that in the model. By adopting this model update approach, the authors develops a novel model-based reinforcement learning algorithm called the Model Gradient algorithm (MG).
Experimental results demonstrate that MG outperforms other model-based reinforcement learning baselines with supervised model fitting in multiple continuous control tasks. MG especially exhibits stable performance in sparse reward tasks, even when compared to state-of-the-art Dyna-style model-based reinforcement learning methods with short-horizon rollouts.
For the future work, this research considers extending this form to more policy optimization such as off-policy methods.
DOI: 10.1007/s11704-023-3150-5
Journal
Frontiers of Computer Science
DOI
10.1007/s11684-023-1046-2
Method of Research
Experimental study
Subject of Research
Not applicable
Article Title
Assessment of HER2 status in extramammary Paget disease and its implication for disitamab vedotin, a novel humanized anti-HER2 antibody-drug conjugate therapy
Article Publication Date
15-Aug-2024



{kind=link}