Recently, the team led by Professor Xu Chengzhong and Assistant Professor Li Zhenning from the University of Macau’s State Key Laboratory of Internet of Things for Smart City unveiled the Context-Aware Visual Grounding Model (CAVG). This model stands as the first Visual Grounding autonomous driving model to integrate natural language processing with large language models. They published their study in Communications in Transportation Research.
Credit: Communications in Transportation Research, Tsinghua University Press
Recently, the team led by Professor Xu Chengzhong and Assistant Professor Li Zhenning from the University of Macau’s State Key Laboratory of Internet of Things for Smart City unveiled the Context-Aware Visual Grounding Model (CAVG). This model stands as the first Visual Grounding autonomous driving model to integrate natural language processing with large language models. They published their study in Communications in Transportation Research.
Amidst the burgeoning interest in autonomous driving technology, industry leaders in both the automotive and tech sectors have demonstrated to the public the capabilities of driverless vehicles that can navigate safely around obstacles and handle emergent situations. Yet, there is a cautious attitude among the public towards entrusting full control to AI systems. This underscores the importance of developing a system that enables passengers to issue voice commands to control the vehicle. Such an endeavor intersects two critical domains: computer vision and natural language processing (NLP). A pivotal research challenge lies in employing cross-modal algorithms to forge a robust link between intricate verbal instructions and real-world contexts, thereby empowering the driving system to grasp passengers’ intents and intelligently select among diverse goals. In response to this challenge, Thierry Deruyttere and colleagues inaugurated the Talk2Car challenge in 2019. This competition tasks researchers with pinpointing the most semantically accurate regions in front-view images from real-world traffic scenarios, based on provided textual descriptions.
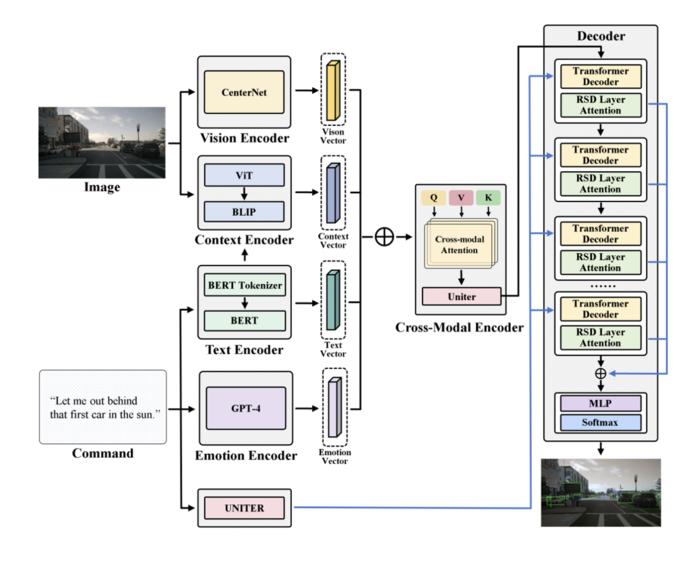
Owing to the swift advancement of Large Language Models (LLMs), the possibility of linguistic interaction with autonomous vehicles has become a reality. The article initially frames the challenge of aligning textual instructions with visual scenes as a mapping task, necessitating the conversion of textual descriptions into vectors that accurately correspond to the most suitable subregions among potential candidates. To address this, it introduces the CAVG model, underpinned by a cross-modal attention mechanism. Drawing on the Two-Stage Methods framework, CAVG employs the CenterNet model for delineating numerous candidate areas within images, subsequently extracting regional feature vectors for each. The model is structured around an Encoder-Decoder framework, comprising encoders for Text, Emotion, Vision, and Context, alongside a Cross-Modal encoder and a Multimodal decoder. To adeptly navigate the complexity of contextual semantics and human emotional nuances, the article leverages GPT-4V, integrating a novel multi-head cross-modal attention mechanism and a Region-Specific Dynamics (RSD) layer. This layer is instrumental in modulating attention and interpreting cross-modal inputs, thereby facilitating the identification of the region that most closely aligns with the given instructions from among all candidates.
Furthermore, in pursuit of evaluating the model’s generalizability, the study devised specific testing environments that pose additional complexities: low-visibility nighttime settings, urban scenarios characterized by dense traffic and intricate object interactions, environments with ambiguous instructions, and scenarios featuring significantly reduced visibility. These conditions were designed to intensify the challenge of accurate predictions. According to the findings, the proposed model establishes new benchmarks on the Talk2Car dataset, demonstrating remarkable efficiency by achieving impressive outcomes with only half of the data for both CAVG (50%) and CAVG (75%) configurations, and showing superior performance across various specialized challenge datasets.
Future endeavors in research are poised to delve into advancing the precision of integrating textual commands with visual data in autonomous navigation, while also harnessing the potential of large language models to act as sophisticated aides in autonomous driving technologies. The discourse will venture into incorporating an expanded array of data modalities, including Bird’s Eye View (BEV) imagery and trajectory data among others. This approach aims to forge comprehensive deep learning strategies capable of synthesizing and leveraging multifaceted modal information, thereby significantly elevating the efficacy and performance of the models in question.
About Communications in Transportation Research
Communications in Transportation Research was launched in 2021, with academic support provided by Tsinghua University and China Intelligent Transportation Systems Association. The Editors-in-Chief are Professor Xiaobo Qu, a member of the Academia Europaea from Tsinghua University and Professor Shuai’an Wang from Hong Kong Polytechnic University. The journal mainly publishes high-quality, original research and review articles that are of significant importance to emerging transportation systems, aiming to become an international platform and window for showcasing and exchanging innovative achievements in transportation and related fields, to promote the exchange and development of transportation research between China and the international academic community. It has been indexed in ESCI, Ei Compendex, Scopus, DOAJ, TRID and other databases. In 2022, it was selected as a high-starting-point new journal project of the “China Science and Technology Journal Excellence Action Plan”.
Journal
Communications in Transportation Research
DOI
10.1016/j.commtr.2023.100116
Article Title
GPT-4 enhanced multimodal grounding for autonomous driving: Leveraging cross-modal attention with large language models
Article Publication Date
21-Feb-2024

